

- share :
従来の検索エンジンに代わる存在として、AI検索エンジン「Perplexity(パープレキシティ)」が注目を集めています。Perplexityは、情報収集のあり方を根本から変えようとしている技術です。
しかし多くのメリットを提供する一方で、このサービスには著作権やセキュリティといった面での深刻な問題が指摘されています。
本記事では、Perplexityが提供する新しい情報体験の魅力と、ビジネスとしてDX(デジタルトランスフォーメーション)を推進する上で見過ごせないリスクの両面を、中小企業の視点から解説します。
【本記事の要点】
- 従来のリンク集形式から脱却した「回答エンジン」Perplexityによる情報収集の高速化
- 大手報道機関との著作権侵害訴訟にみる「ゼロクリック検索」がもたらす経済的損失と倫理的課題
- 間接的プロンプトインジェクション等、AI搭載ブラウザ特有の未知のセキュリティ脆弱性
- 技術の利便性と知的財産権保護を両立させるための社内利用ガイドライン策定の必要性
検索の常識を変える「回答エンジン」Perplexity
2022年に公開されたPerplexityは、従来の検索エンジンのあり方を覆す可能性を秘めたサービスです。Amazonのジェフ・ベゾス氏やNVIDIAといった著名な企業から支援を受け、2024年6月にはソフトバンクとの提携も発表されました。日本国内でも急速に知名度を上げ、「パープレ」の愛称で親しまれています。
Google検索や一般的な生成AIとの決定的な違い
Googleに代表される従来の検索エンジンは、ユーザーが入力したキーワードに対し、関連性の高いウェブサイトのリンク集を提供します。情報を探すための「道案内役」のような役割といえるでしょう。
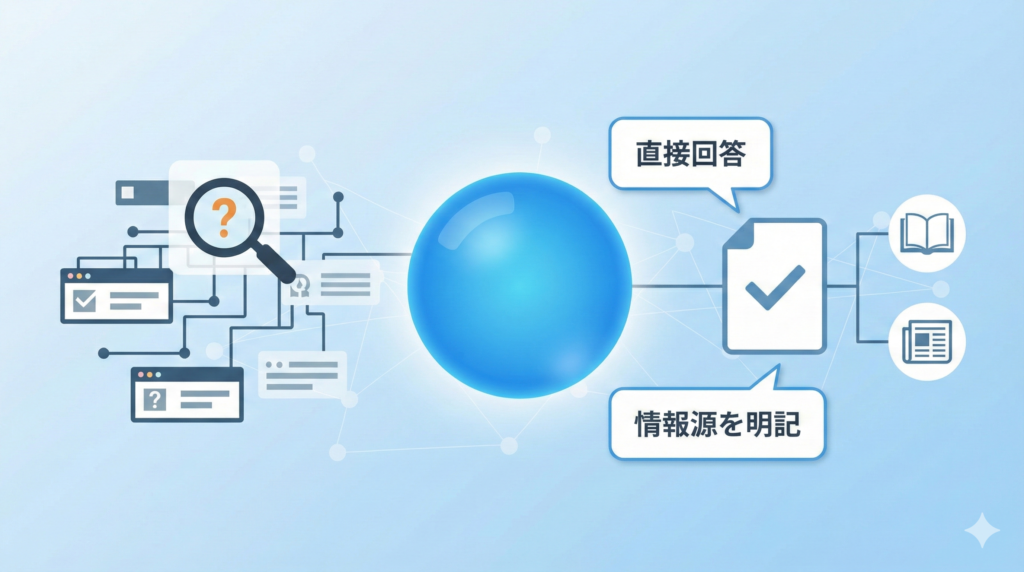
一方、Perplexityは、ユーザーの質問に対し、WEB上の複数の情報源をもとにAIが直接回答を生成する「回答エンジン」として機能します。この点で、従来の検索エンジンとは一線を画しています。
さらに、ChatGPTなどの一般的なチャットボット型生成AI(大規模言語モデル:LLM)との決定的な違いは、回答の根拠となる情報源(引用元)を必ず明記する点です。一般的な生成AIが、学習データに基づき「もっともらしい」答えを生成するのに対し、Perplexityは「WEB上の公開情報」をリアルタイムで検索し、その具体的な出所を示しながら回答を構成するのです。
質問に対する答えそのものが提示されるため、ユーザーは複数のリンクを巡回する手間をかけることなく、必要な情報に素早くアクセスすることが可能です。PerplexityのCEOアラビンド・スリニバス氏も「少ないことは豊かなこと(Less is more)」という哲学のもと、情報過多に陥りがちな従来の検索体験を改善したいと語っています(参考:創業2年のパープレキシティが挑む、「Google」という常識の再考 CEO来日インタビュー/TECHBLITZ)。
Perplexityが支持される理由
Perplexityが急速に支持を広げた要因は、その利便性と信頼性にあります。Perplexityに搭載されたAIが生成した回答には、その根拠となる引用元が明記されます。これにより、ユーザーは情報の出所を容易に確認でき、回答の信頼性を自ら判断することが可能です。また、広告や余計なリンクが表示されないため、ノイズのない効率的な情報収集が可能となります。
この新しい体験は、人々がキーワードで「検索」する時代から、AIに直接「質問」する時代への転換を予感させるものです。業務効率化を目指す中小企業にとって、AIを活用した情報収集はDXを加速させる強力な武器となり得るでしょう。
著作権問題が引き起こす「AIとメディアの対立」

急速な成長の裏で、Perplexityはコンテンツの権利者、特に報道機関との深刻な対立に直面しています。AIが学習や回答生成の過程で、著作物を無断で利用しているとして、世界中で訴訟が相次いでいるのです。
著作権侵害を巡る世界的な訴訟の激化
日本では、報道業界全体を巻き込む大きな動きに発展しています。2025年8月7日、読売新聞社は日本の大手報道機関として初めてPerplexityを著作権侵害で東京地方裁判所に提訴しました。約21億6,800万円の損害賠償を求めた同社は、2025年2月から6月の間に約11万9千件の記事が無断利用されたと主張しています(参考:読売新聞社、「記事無断利用」生成AI企業を提訴…日本の大手報道機関で初/読売新聞オンライン)。
さらに、2025年8月26日には、朝日新聞社と日本経済新聞社が共同でPerplexityを提訴しました。両社は著作権侵害に加え、生成された回答に虚偽の情報が含まれることで、報道機関としての信用が毀損されたとし、不正競争行為にもあたると主張しました。合計44億円の損害賠償が請求されています(参考:“AI検索サービスで記事無断利用” 朝日 日経が米企業を提訴/NHK NEWS WEB)。
これらの訴訟で共通して問題視されているのが、Perplexityのサービス構造そのものです。ユーザーが元記事を掲載するWEBサイトを訪問することなく回答を得られる「ゼロクリック検索」は、報道機関の広告収入や有料購読といったビジネスモデルを根底から揺るがす脅威と見なされています。
「robots.txt」無視が示す倫理観の欠如
さらに、各新聞社がWEBサイトのクローラーによる自動収集を拒否する意思を示す「robots.txt(ロボッツ・テキスト)」を設置していたにもかかわらず、Perplexityがこれを無視して情報収集を続けていた点も強い非難の対象となっています。
robots.txtとは、WEBサイトの運営者が、検索エンジンのクローラー(情報を自動で収集するプログラム)に対し、「このページやディレクトリにはアクセスしないでほしい」という意思を伝えるためのテキストファイルです。これは、特定の情報を検索結果に表示させたくない場合や、サーバーへの負荷を軽減したい場合などに設置される、WEB上のクローラー利用における基本的なルールであり、一種の紳士協定として機能しています。
Perplexityが、この慣習的なルールを無視して情報収集を続けていたという事実は、単なる著作権侵害にとどまらず、WEB上の慣習や倫理観を軽視しているという印象を抱かせます。DXを推進する上では、技術の利便性だけでなく、その社会的・倫理的側面を考慮することが不可欠です。

執筆者
株式会社MU 代表取締役社長
山田 元樹
社名である「MU」の由来は、「Minority(少数)」+「United(団結)」という意味。企業のDX推進・支援を過去のエンジニア経験を活かし、エンジニア + 経営視点で行う。DX推進の観点も含め上場企業をはじめ多数実績を持つ。